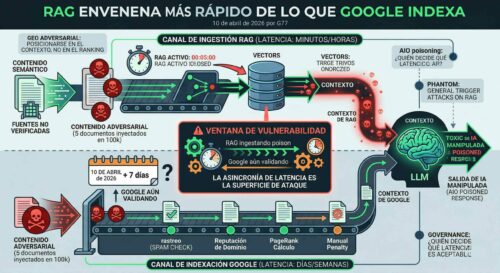
Hay un intervalo de tiempo que casi nadie mide y que está redefiniendo cómo se manipula la información en sistemas de IA. Google tarda días, a veces semanas, en desindexar contenido fraudulento o actualizar su ranking tras una modificación. Un sistema RAG —Retrieval-Augmented Generation— puede consumir y servir ese mismo contenido en cuestión de horas, incluso minutos, dependiendo de cómo esté configurado su pipeline de ingestión. Ese diferencial no es un detalle técnico menor. Es una superficie de ataque.
El ciclo de actualización como vulnerabilidad
Un sistema RAG funciona en dos fases distintas: primero recupera fragmentos relevantes de una base de conocimiento externa, generalmente almacenada como vectores semánticos; luego los usa como contexto para que el modelo genere una respuesta. La calidad de esa respuesta depende directamente de la calidad del contenido indexado. Y ahí está el problema.
Las bases vectoriales que alimentan estos sistemas se actualizan de forma independiente al índice de Google. Algunas organizaciones sincronizan sus RAGs con fuentes web cada pocas horas. Otras mantienen pipelines casi en tiempo real. La investigación de Zhu et al. (2024) sobre envenenamiento de RAG —publicada originalmente como «PoisonedRAG» en arXiv— demostró que inyectando tan solo cinco documentos maliciosos en una base de conocimiento de cien mil entradas, era posible manipular las respuestas del sistema con una tasa de éxito superior al 90% en ciertos tipos de consultas. Cinco documentos. En una base de cien mil.
Esto no requiere comprometer el modelo. No requiere acceso privilegiado. Requiere que el contenido malicioso sea recuperable y semánticamente relevante para la consulta objetivo.
Lo que el SEO clásico no ve
El SEO tradicional opera en un marco donde Google es el árbitro final. Existe toda una industria construida alrededor de entender cómo funciona el Googlebot, cuándo rastrea, qué señales pondera, cómo se penaliza el contenido de baja calidad. Los mecanismos de defensa están razonablemente maduros: detección de spam, sistemas de reputación de dominio, penalizaciones manuales.
Pero ese marco asume un único punto de indexación con criterios públicos y relativamente conocidos. Los sistemas RAG lo fragmentan radicalmente. Cada organización que despliega un RAG toma sus propias decisiones sobre qué fuentes incluir, con qué frecuencia actualizarlas, qué filtros aplicar antes de la ingestión y qué modelo de embeddings utiliza para construir el espacio vectorial. No existe un Googlebot único. Existen miles de crawlers propietarios, cada uno con su propia lógica de confianza.
El resultado práctico es que un atacante puede publicar contenido diseñado para ser ingerido por un RAG específico sin que ese contenido haya sido validado por ninguna señal de reputación equivalente al PageRank. Y puede hacerlo antes de que cualquier sistema de detección de spam haya tenido tiempo de reaccionar.
GEO adversarial: posicionarse en el contexto, no en el ranking
La disciplina emergente del GEO —Generative Engine Optimization— estudia cómo optimizar contenido para que los motores generativos lo recuperen y citen. El paper fundacional de Aggarwal et al. (2023), «GEO: Generative Engine Optimization», identificó que ciertas características textuales —citas de autoridad, estructura de respuesta directa, densidad de entidades nombradas— incrementaban significativamente la probabilidad de que un sistema RAG recuperara un fragmento sobre alternativas disponibles.
Lo que ese paper describía como optimización legítima tiene, naturalmente, su reverso adversarial. Si conoces los criterios por los que un RAG selecciona fragmentos, puedes construir contenido que los satisfaga artificialmente. No necesitas ser la fuente más precisa. Necesitas ser la fuente más recuperable para una consulta específica. La diferencia entre ambas cosas puede ser enorme.
Este es el espacio donde opera el AIO poisoning —AI Output poisoning— como extensión del envenenamiento clásico de LLMs. No se ataca el modelo directamente. Se ataca el contexto que el modelo recibe. Y ese contexto llega por canales que los sistemas de defensa convencionales no monitorizan.
La ventana que nadie cierra
El problema estructural es de asincronía. Los mecanismos de defensa —tanto los de Google como los de los propios sistemas RAG— operan con latencias distintas e incompatibles entre sí. Un contenido puede ser detectado como spam por Google en siete días y haber sido ingerido, vectorizado y servido como contexto authoritative por tres sistemas RAG distintos durante esos mismos siete días.
Investigadores como Cheng et al. en «Phantom: General Trigger Attacks on Retrieval Augmented Language Generation» () han formalizado esta asimetría: los ataques sobre RAG son fundamentalmente más rápidos que los mecanismos de detección diseñados para entornos de búsqueda estática. La velocidad es estructural, no accidental.
Las organizaciones que despliegan RAGs en producción están tomando decisiones de actualización basadas en criterios de frescura informativa —quieren datos recientes— sin medir simultáneamente el riesgo que esa frescura introduce. Actualizar más rápido no es solo una ventaja competitiva. Es también una ventana que permanece abierta más tiempo.
La pregunta que queda sin resolver no es técnica. Es de gobernanza: ¿quién decide qué latencia de ingestión es aceptable cuando no existe ningún estándar sectorial que obligue a medirla?